
Combined methods for gender inference
Combined method presented here (M3) works on both images and names.
To see how this method performs in comparison with others, please visit performance page
M3
M3 is a Python-based deep learning model trained to infer socio-demographic attributes, including gender. The model can infer gender both on images and names only. However, it works best when using both images and names.
How it works
M3 was trained on a massive Twitter dataset to infer socio-demographics based on a person's image and name. It features three major attributes:
- Multimodal. M3 takes both vision and text inputs. Particularly, the input may contain a profile image, a name (e.g., in the form of a natural language first and last name), a user name (e.g., the Twitter screen_name), and a short self-descriptive text (e.g., a Twitter biography).
- Multilingual. M3 operates in 32 major languages spoken in Europe. They are ['en', 'cs', 'fr', 'nl', 'ar', 'ro', 'bs', 'da', 'it', 'pt', 'no', 'es', 'hr', 'tr', 'de', 'fi', 'el', 'he', 'ru', 'bg', 'hu', 'sk', 'et', 'pl', 'lv', 'sl', 'lt', 'ga', 'eu', 'mt', 'cy', 'rm', 'is', 'un'] in ISO 639-1 two-letter codes (un stands for languages that are not in the list).
- Multi-attribute. Thanks to multi-task learning, the model can predict three demographic attributes (gender, age, and human-vs-organization status) at the same time.
Installation
You can install a python package m3inference using pip, which also installs necessary libraries (for problems with some packages please refer to the Github page):
pip install m3inference
How to use
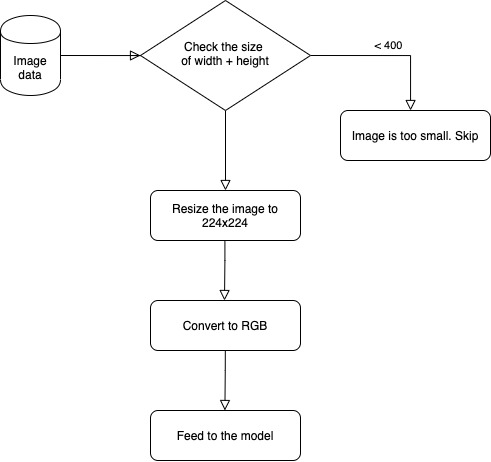
After you install the library, in case you use photos, you should preprocess your images to get them resized to the correct shape. You can use a preprocess script or create your own (refer to the documentation for the details). Initiate an object of M3Inference() and then use the function infer() with a json file as an input.
For other model settings (e.g., output format, GPU setting, batch size, etc.), please use the file test/data.jsonl on github page as a sample input file and see the docstrings for M3Inference initialization and infer method for detailed utilization.You can also explore M3 using the web demo or the executable python notebooks powered by Binder (see below).
You can try out this method with executable python notebooks powered by Binder. Click the button below to launch it and follow the instructions:
Binder is a service that deploys computing environments on the cloud.
Keep in mind that these notebooks are made for demonstration of the method and are not designed for large datasets.
Input
M3 works best when making inferences on visual and textual input together, but you can also use it with only visual or only textual input. It takes a JSON file as an input, which should have the following keys:
- id (should be a unique random number);
- name (name in string format, if you only want to use image-based M3, insert an empty string here);
- screen_name (this field refers to a Twitter profile screenname; you can leave it empty if you do not use Twitter data);
- description (this field refers to a Twitter profile bio; you can leave it empty if you do not use Twitter data);
- lang (language in ISO format in case you have such data, otherwise empty);
- img_path (path to each image file);
- In case you use Twitter data, for lang, even if the official Twitter JSON entry contains this field, it is recommended to try to use the cld2 wrapper method (from m3inference import get_lang) to get the language either from the user's biography/description or the user's tweets. You could also hard-code the language if you know the ground truth.
- Images can also be downloaded from Twitter as 400x400 pixel images. Note that you must resize your photos to 224x224 pixels using the pre-processing code mentioned above.
Output
The output file is a Python dictionary in which the ids are the keys. The predictions are included as corresponding values. Predicted attributes are gender, age, and human-vs-organization status - a binary category indicating whether the image is associated with an organization rather than a person. The values represent probabilities for each category, ranging between 0 and 1.
After running the code for inference you should see the following output:

Below is an example from the demo notebook using an image only (i.e., without textual input). The current threshold for the resulting gender is 50% (meaning that the gender with the maximum probability will be returned).


Augmenting your data
M3 was trained on full Twitter data and, therefore, performs better with visual and textual data. If you have a dataset with only names, you can enrich your data with images using this method. It extracts the top five images from Google Search using the name as a query. This way, you can use M3 as a mixed method.
➤